As researchers who examine phenomena within and around organizations, industrial and organizational psychologists must deal with nested data. Consider that individuals are nested within job categories, job categories are nested within work groups, work groups are nested within departments, departments are nested within organizations, and organizations are nested within nations and cultures. Furthermore, people do not enter these jobs and organizations in random ways; rather, people choose which organizational environments to enter, and organizations choose which people to select and retain. All of this leads to the important observation that much of the data obtained in organizational settings is unlikely to be independent within units. This, in turn, carries a statistical consequence: that some key assumptions of our tried-and-true statistical methods (regression and analysis of variance, or ANOVA) are likely to be violated in most organizational research.
Recently, several theoretical, methodological, and statistical advancements have made multilevel research more feasible. This entry focuses on one particularly useful statistical advancement, hierarchical linear modeling (HLM). This regression-based approach is useful for testing the presence of higher-level (contextual) effects on lower-level relationships and outcomes.
Academic Writing, Editing, Proofreading, And Problem Solving Services
Get 10% OFF with 24START discount code
Statistical Consequences of Nested Data
The general linear model, which subsumes both regression and ANOVA, assumes that errors are independent and normally distributed, with a mean of zero and a constant variance. Yet when the data are nested—for example, when the behaviors and attitudes of individuals within a team are affected by teammates—this assumption is violated. This is known as nonindependence, and its major consequence is that standard errors are smaller than they should be, which, in turn, contributes to inflated Type I errors. There are other, more subtle effects of non-independence that can cause problems with estimation of effect size and statistical significance; the References: section contains links for more details.
Nonindependence is most frequently documented by the intraclass correlation coefficient. When non-independence exists, the use of HLM becomes problematic; however, we now have the tools to more directly model the data in such situations.
A Nontechnical Introduction to HLM
Many references to the technical details of HLM are provided in the References: section. The purpose of this entry is only to introduce the concept, and this is done through the use of figures and an example. Figure 1 shows a simple example in which organizational climate is hypothesized to influence individual job satisfaction directly, as well as the relationship between satisfaction and pay. This hypothesis can be represented in terms of two levels. In the Level 1 model, job satisfaction can be regressed on pay. One would expect a positive relationship, such that higher pay is associated with more job satisfaction. However, what if multiple organizations were sampled and it was found there are mean differences in satisfaction across organizations, as well as differences in the relationship between pay and job satisfaction? Such a situation might occur when individuals within an organization share at least some common sources of influence, hence the nonindependence of their job satisfaction scores.
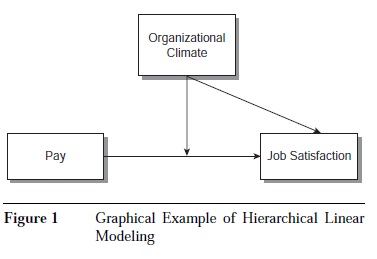
The between-organization differences could be explained by organizational climate. Note that organizational climate would be considered a Level 2 predictor because the Level 1 scores are nested within organizations. Hence, one could determine whether organizational climate directly explains mean organizational differences in job satisfaction and whether the relationship between pay and satisfaction differs as a function of climate. The hypothesis might be that favorable climates enhance satisfaction and weaken the relationship between pay and satisfaction.
Thus, HLM offers the ability to link predictors at multiple levels of analysis with a dependent variable at a lower level of analysis. In the following section, some examples of research questions are provided in which HLM is most appropriate and necessary.
Common Industrial and Organizational Research Questions That Require HLM
Hierarchical linear modeling is not necessary or even appropriate for all research questions. As reviewers and readers of the literature, we believe it is sometimes overused. In this section, examples illustrate HLM when it is most appropriate. For the sake of brevity, two major categories of applications of HLM will be considered, as well as the substantial research questions that can be addressed.
The first type of application supports a mixed-determinants model. This is the model described in Figure 1, which illustrates situations in which the dependent variable or criterion is at the lowest level of analysis and the independent variables or predictors are at the same or higher levels. In this case, the higher-level variable explains between-group and between-organization variance, and the lower-level variable explains within-group and within-organization variance. With regard to these models, researchers have identified four primary research questions that can be answered by HLM: (a) Does the unit in which individuals work make a difference? (b) What is the impact of individual differences across units? (c) Are individuals influenced by characteristics of the unit? and (d) Do unit properties modify individual-level relationships?
The second type of application in which HLM has proved useful is the analysis of longitudinal data. Longitudinal research questions are multilevel questions because the repeated observations within a person over time (Level 1) are nested within a person (Level 2). Such models are called growth curve models, and they need not occur only at the individual level; any repeated observations within a person, group, or organization can be modeled using growth models. Key questions of interest with growth models include the following: (a) Do individual differences change over time (intraindividual change)? (b) What pattern of change does the outcome variable follow over time (e.g., linear, nonlinear)? (c) Are there between-person differences in the change patterns (interindividual differences in intraindividual change)? and (d) Why are there individual differences in the change patterns? The advantage of applying HLM to these longitudinal models comes from its capability to simultaneously analyze intraindividual and interindividual differences, handle missing data and unequal measurement periods, and model correlated errors.
For example, one may want to understand how performance changes over time and the factors that explain this performance change. Suppose a researcher hypothesizes that (a) performance will follow a curvilinear pattern over time; (b) there are significant individual differences in performance change over time; and (c) personality explains these individual differences in patterns of change. In this situation, the Level 1 model has the repeated performance observations as the criterion and time as the independent variable (time may be structured in a variety of ways to test different patterns of change). Provided there are individual differences in patterns of change, we can determine whether these differences are explained by the Level 2 personality predictor.
Summary
Although the origins of HLM can be traced back to decades of educational research, its applications in industrial/organizational psychology and organizational behavior have just begun to appear. Yet the timing could not be better: We now fully realize that many organizational phenomena are inherently nested and hierarchical. Hierarchical linear modeling has already been applied to such diverse topics as modeling the interaction between the individual and situation, understanding the dynamic nature of performance criteria, and illustrating the moderating effects of leadership climate, to name just a few examples. This technique is not a solution for all such questions; rather, it is most useful for questions in which the predictors exist at multiple levels and the criterion exists at the lowest level of analysis (this is true in both mixed-determinants models and growth models). These questions are frequently of great interest to organizational scholars. Therefore, HLM will likely continue to grow in application and help us to test our multilevel theories of organizational behavior.
References:
- Bliese, P. D. (2002). Multilevel random coefficient modeling in organizational research: Examples using SAS and S-PLUS. In F. Drasgow & N. Schmitt (Eds.), Measuring and analyzing behavior in organizations: Advances in measurement and data analysis (pp. 401-445). San Francisco: Jossey-Bass.
- Bliese, P. D., & Ployhart, R. E. (2002). Growth modeling using random coefficient models: Model building, testing, and illustration. Organizational Research Methods, 5, 362-387.
- Hofmann, D. A., Griffin, M. A., & Gavin, M. B. (2000). The application of hierarchical linear modeling to organizational research. In K. J. Klein & S. W. J. Kozlowski (Eds.), Multilevel theory, research, and methods in organizations: Foundations, extensions, and new directions (pp. 467-511). San Francisco: Jossey-Bass.
- Klein, K. J., & Kozlowski, S. W. J. (2000). A multilevel approach to theory and research in organizations: Contextual, temporal, and emergent processes. In K. J. Klein & S. W. J. Kozlowski (Eds.), Multilevel theory, research, and methods in organizations: Foundations, extensions, and new directions (pp. 3-90). San Francisco: Jossey-Bass.
- Ployhart, R. E., Holtz, B. C., & Bliese, P. D. (2002). Longitudinal data analysis: Applications of random coefficient modeling to leadership research. Leadership Quarterly, 13, 455-486.
- Raudenbush, S. W., & Bryk, A. S. (2002). Hierarchical linear models: Applications and data analysis methods (2nd ed.). Newbury Park, CA: Sage.